Google Summer of Code 2017
Introduction
In Google Summer of Code 2017 I worked upon an interesting problem of flattening non-static PDF form contents for the purpose of printing. PDF files are capable of containing an interactive form with which users can interact using a PDF viewer application. Users can fill the data, change the data and save it. The aim of my project was to provide a mechanism to flatten (convert the dynamic content into static) the PDF files. I was mentored by Till Kamppeter and Jay Berkenbilt and guided extensively by Tobias Hoffman.
Problem background and solution
A bug report was generated here describing the problem that CUPS-filters is unable to print the filled PDF form data. The bug can be regenerated by using following command
$ lp -o fit-to-pagefilled-PDF-form
CUPS-filters uses QPDF internally for performing all PDF related transformations. QPDF is capable of performing linearization, encryption, decryption etc. As CUPS-filters uses this library to handle all its PDF related tasks, the support for flattening the PDFs was found missing in QPDF. Thus, the problem can be solved by adding PDF flattening support to QPDF and then CUPS-filters can easily leverage this functionality.
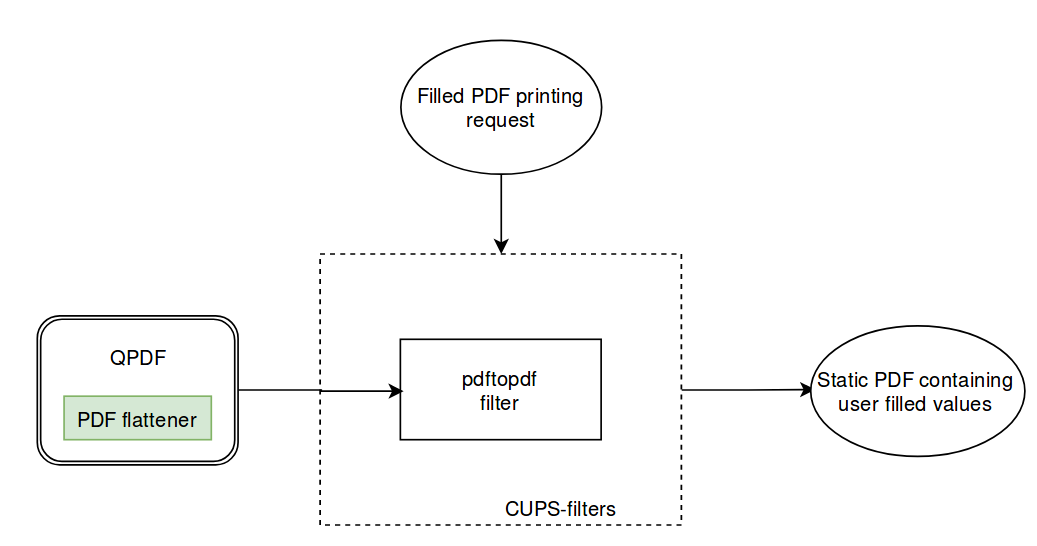
How to achieve PDF flattening?
PDF reference in sections 8.4 and 8.6 describes how the interactive form (also called as AcroForm) represented in a PDF file and what all are the attributes associated with them. So for every page present in the PDF file, all the form fields can be traversed one by one and worked upon. There are two cases which needs to be considered while flattening a PDF which depends upon when a key named /NeedAppearances is set to false (or the key is not present) or true. The key basically indicates whether the PDF viewer application needs to reconstruct the apperances of the AcroForm fields.
Case 1
When the /NeedAppearances is set to false or the key is missing, then the task becomes quite simple. There is not need to reconstruct the apperances of the AcroForm fields. All the fields in the AcroForm are represented as dictionaries with various attributes like the appearance of this filed (/N key), the value of this fields (/V key) or te resources used by this field (/Resources key). In this case all the appearances can just be given a unique name (using /Name key) and they can be added to the resources of the page.
Case 2
Sometimes, when the values of the PDF form are already known, the PDF viewers save the forms as streams instead of just dictionaries and then set the /NeedAppearances key to true. When the PDFis opened, the appearances needs to be dynamically reconstructed by PDF viewer and if the values are modified then a new appearance stream has to be generated. In this case, the fields have to be visited recursively (if they have kids) and their appearances have to be regenerated as per the field type. Section 8.6.2 of the PDF reference describes in detail how we can achieve that.
Progress and future work
As of now, the flattener supports PDFs conforming to case 1. Work is still in progress for case 2. Though case 1 is complete, there are still minor issues with it. After completing the flattener, extensive testing has to be performed. When the flattening support is added in QPDF, CUPS-filters has to be modified (especially pdftopdf filter) for performing flattening before it starts working on the PDF.
The project is hosted on Github currently as a standalone tool. You can find it here. If you have any suggestions you can mail me or if you want to contribute to it feel free to fork it.
A vote of thanks
I would like to thank The Linux Foundation for providing me with the opportunity to work on one of the best problems I have ever encountered. I would like to specially thank Till for letting me continue working on the project despite the difficulties I was facing. Tobias has been an excellent guide and without him I think the project would have taken a long long time to get into motion and I am extremely grateful to him for that. I thank Jay for helping me out with intricacies of QPDF.